In 2026, the bottleneck in enterprise software delivery is not how fast a developer can write code, but coordination, context, governance, and rework. Those are the things that consume calendar time. A team that ships a feature in six weeks is not slow because the developers were typing too slowly. The team is slow because requirements were ambiguous, handoffs lost context, reviews surfaced misalignment late, and the same problem got rebuilt twice. None of that is solved by giving each developer a faster autocomplete.
I gave a tech-talk recently on what actually compresses the pipeline, and I want to capture the substance of it here for those who couldn’t attend live. The short version is this: AI compresses delivery when it operates against a governed specification, with role-based agents, human gates at every handoff, and full traceability from business intent to merged code. Anything short of that is one-seat acceleration dressed up in enterprise language.
A practical mental model for working with LLMs
Large language models (LLMs) generate text by predicting the next token based on the input they’re given. That makes them powerful, but also sensitive to how information is structured and presented since they don’t actually “think.”
Before we get into delivery architecture, it helps to be honest about how these models actually behave, because most prompting failures come from misunderstanding the basics.
Three things matter operationally.
The first is context. Models attend only to what is in the context window, and irrelevant text dilutes the signal.
The second is attention. Prompts compete for the model’s focus, and clear structure with explicit hierarchy guides what the model treats as important.
The third is token prediction. Outputs are generated one token at a time, conditioned on what came before. This means deterministic structure beats vague descriptions. Constraining the format and scope produces reliable outputs, while asking the model to “do something good” may or may not deliver the intended results.
That gives you three levers to pull. You provide the right context, not just more context. You define constraints, including roles, rules, acceptance criteria, and explicit non-goals, so the model has a fence around its creativity. You provide examples that show the exact shape you want, because the model will pattern-match on the example more reliably than on a description of the example.
These are baseline techniques rather than advanced ones, and teams that skip them spend their time on hallucinated APIs, requirements that drift mid-conversation, refactors that expand scope without permission, and inconsistent outputs across runs that look superficially correct.
Prompting works for one person. Teams need specs.
Prompting versus specs is where most enterprise AI conversations stall. The prompting techniques described above work very well for an individual contributor on a contained task, but they scale poorly across a team, across a sprint, and across a delivery pipeline. That is not a limitation of the techniques themselves; it is simply a feature of what prompts actually are. A prompt is ephemeral. It exists in a chat window, gets consumed by the model, and produces an output that is not reproducible, reviewable, or auditable. That works for a developer exploring a problem, but it does not work for an enterprise delivery system.
What scales across a team is a specification. The spec, not the prompt, becomes the source of truth. Code is derived from the spec, which is versioned, reviewed, and governed. Every phase of the pipeline consumes a spec and produces the next artifact, which is itself reviewable. That is the difference between ad hoc prompting and spec-driven development, and it matters because specs are the only way to get reproducible artifacts, formal review, and a traceable line from business intent through to a merged pull request.
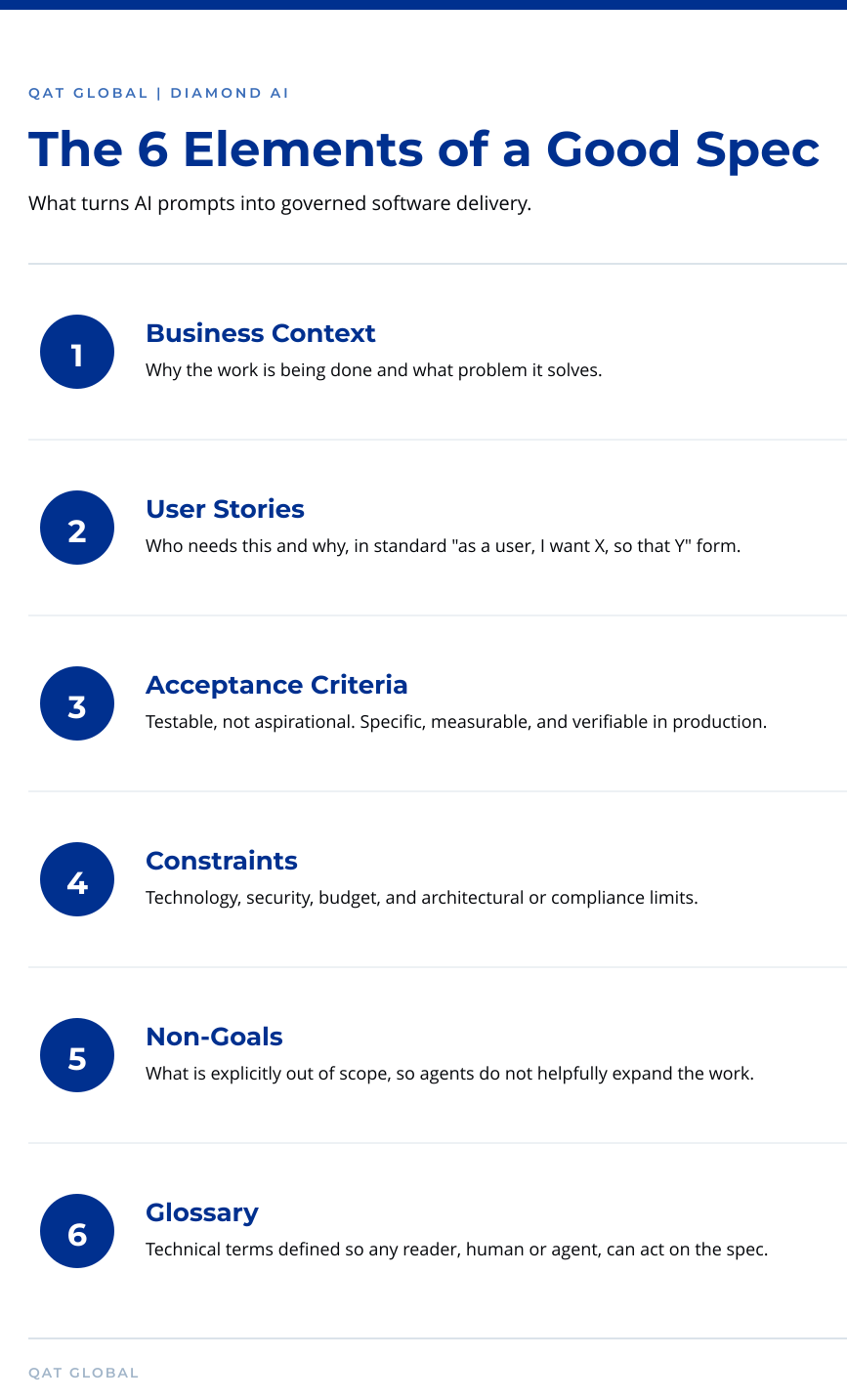
A good spec is not a fifty-page document. In our experience, one or two-page specs are usually enough, but those pages have to do specific work. We look for six elements.
The first is business context, which establishes why the work is being done and what problem it solves.
The second is user stories, expressed in the standard “as a user, I want X, so that Y” format.
The third is acceptance criteria, written to be testable rather than aspirational. A statement like “the system should be fast” is aspirational, while “the page must load in under two seconds at the 95th percentile” is testable.
The fourth is constraints, including technology requirements, security requirements, budget, and any architectural or compliance limits.
The fifth is non-goals, which is often the most overlooked and the most valuable, because explicitly stating what is out of scope prevents an AI agent from helpfully expanding the work.
The sixth is a glossary of technical terms so that a new team member or an agent can read the spec and immediately understand what is being built.
When a spec contains those six pieces, it becomes a contract that any agent or human in the pipeline can act on without ambiguity. When it does not, you are back to chat logs, tribal knowledge, and inconsistent runs.
What governed agentic delivery actually looks like
At QAT Global, we built Diamond AI to operationalize spec-driven delivery as a governed pipeline rather than a productivity feature. The methodology has five phases, and the key characteristic is that each phase produces an artifact that the next phase consumes, with a human gate at each handoff.

Phase one is requirements. Business documentation, structured information, and existing specs are gathered and validated, and the output is a specification ready to be planned against.
Phase two is project planning, where the spec becomes a backlog, a project plan, and an architecture. The human gate at this stage answers a single question: Can we actually build this?
Phase three is development, where the architecture and plan become implemented code, and the human gate here asks whether the code matches the plan.
Phase four is quality assurance, where the code becomes tests, including unit, end-to-end, and load tests as appropriate. The human gate asks whether the work is production-ready, and that is typically where a tech lead, an architect, or a senior developer reviews the pull request against the original specification.
Phase five is deployment, which proceeds only after every prior gate has been cleared.
The agents in this pipeline are role-based. We run an analyst agent, a product management agent, an architect agent, a developer agent, and a quality assurance agent. Each one reads the artifact produced by the prior phase, performs its scoped work, and hands off to the next agent under human supervision. That structure is what makes the pipeline both fast and reviewable, and it is what makes Diamond AI different from a coding assistant, which gives one developer help inside an editor and produces no governance trail.
I want to flag one thing that surprises people, because it surprised us at first. With AI in the pipeline, we are, in some respects, moving back toward waterfall. I do not mean that in the bureaucratic sense, but in the sense that AI agents will only build what you specify, which means the upfront definition work becomes load-bearing in a way it was not under pure agile execution. Teams that try to keep their old “we will figure it out in the sprint” habits while plugging in AI agents get the worst of both worlds, and the teams that invest in clean specifications upfront get the compression they were promised.
Making AI cost visible at the unit of work
There is one operational reality that does not get enough attention in AI delivery conversations, and that is cost. Most enterprises using LLM APIs find out what their AI usage actually costs at the end of the month, when the bill arrives. That is not acceptable for any other production system, and it should not be acceptable for AI either.
We built Diamond AI to track every interaction at the work-item level. When the pipeline runs against a backlog item, we record the cost of each workflow step and surface a per-task cost in the dashboard. If task 419 costs fifty cents to run through the full agentic pipeline, that number is visible the moment the work completes, and it is broken down by workflow stage. That visibility changes the conversation from “how much did we spend on AI last month” to “what is the unit economics of agentic delivery against this backlog,” which is the question enterprise leaders actually need answered before they scale.
The takeaway
We covered a lot in my latest Tech-talk: LLM fundamentals, prompting techniques, spec-driven development, and the Diamond AI methodology, with its five governance phases and role-based agents. The single thread running through all of it is that AI compresses delivery not by making developers code faster, but by compressing the entire pipeline from business documentation to production-ready features, with governance and human review preserved at every step.
If your team is using coding assistants and seeing individual productivity gains without corresponding pipeline compression, the issue is not that the assistants are failing. The architecture around them is incomplete, and the acceleration is happening in the wrong layer of your delivery system.

What comes next
If any of this resonates with where your delivery organization is right now, we run a Diamond AI strategy session for enterprise technology leaders who want to see what governed agentic delivery looks like against a real feature in their environment. The first month is an assessment, where we work with you to identify the right business case, then run it through the Diamond AI workflow. The output is a complete artifact set including requirements, architecture, code, and tests, along with measurable time-to-value data from the run. After that, you have actual evidence of what the pipeline looks like in your environment, and you can decide whether it makes sense to scale.
Visit qat.ai/accelerate to book a session.





